Learning Objectives
After completing this lesson, you’ll be able to:
- Identify null and missing attribute values.
- Set null and missing attribute values.
- Filter out null and missing attribute values from your data.
Resources
Introduction
In this workspace, a colleague is trying to write out a list of parks to a Geodatabase dataset. It’s important that the parks are in alphabetical order – according to their name – and that features with no park names are written as null and appear last in the dataset.
However, the workspace they have does not seem to be doing what they need. The parks are sorted alphabetically, but unnamed parks always appear first.
1) Start Workbench
Open the starting workspace in FME Workbench (2021.1 or later).
Using feature caching, run the workspace and inspect the source dataset as a table. You’ll see that the data is in order of ParkId, not ParkName, and that there are <missing> values scattered throughout:
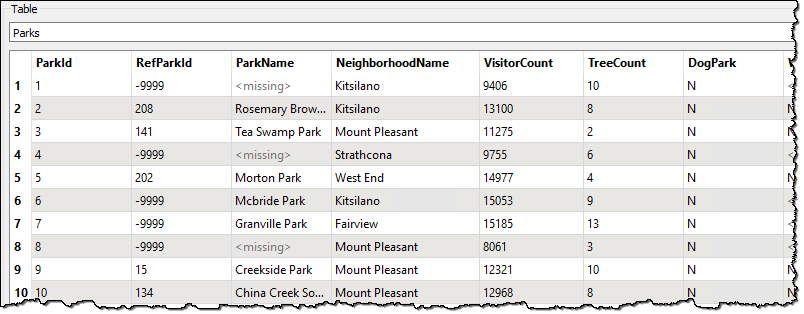
To sort the <missing> data we'll need to set their ParkName attribute to something that appears at the bottom of a sorted list then set them back to <null> afterward.
2) Add NullAttributeMapper
Add a NullAttributeMapper transformer prior to the Sorter transformer. Inspect the parameters.
Ensure “Map” is set to Selected Attributes, and choose the attribute ParkName:

Underneath that is a section of what to map to.
We know the values in here are currently listed as <missing> so set the “If Attribute Value Is” parameter to Missing (Selected Attributes Only)
We want to map these to a value that appears at the bottom of an alphabetically sorted list, so change “Map To” to New Value and enter ZZZ as the new value.
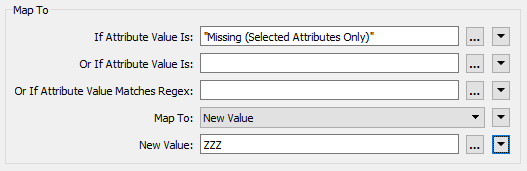
Accept the parameter changes.
3) Add NullAttributeMapper
Now add a second NullAttributeMapper; this time it should be connected after the Sorter.
Open the parameters and, once again, ensure “Map” is set to Selected Attributes and select the ParkName attribute. This time turn the ZZZ values back to nulls:
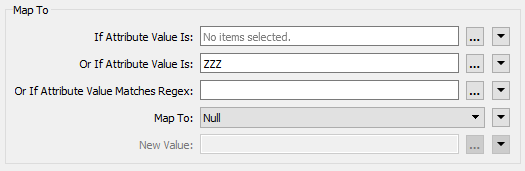
Technically we could just turn them back into <missing>; the Geodatabase writer will write them out as nulls. However, assuming we didn’t know that, null is the safer option and bound to give us what we want.
4) Save and Run Workspace
Save the workspace and then run it. Inspect the output. This time the data should be sorted by ParkName, but with all null values at the end of the dataset:
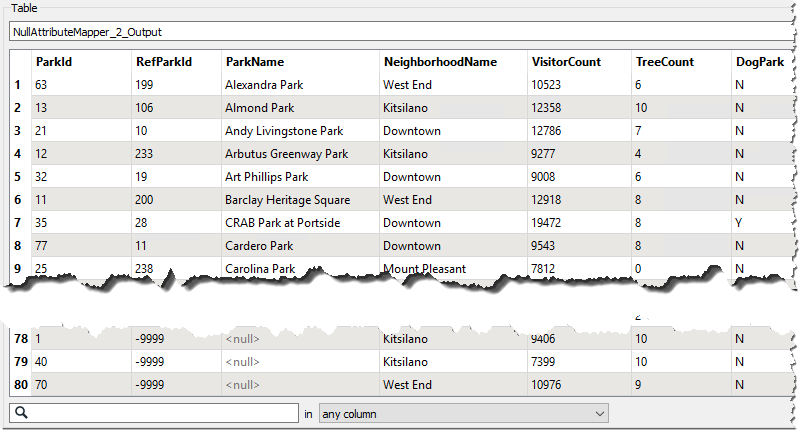
5) Fix RefParkId
Your colleague now asks you to fix the RefParkId field. You'll have noticed that a lot of the values are -9999. That's the MapInfo equivalent of "nothing", but for Geodatabase it would be better to set these to proper nulls.
To do this open the parameters dialog for the first NullAttributeMapper. Add RefParkId to the list of attributes for processing. Then add -9999 to the "Or If Attribute Value Is" field:

Now open the second NullAttributeMapper and add RefParkId to the list of attributes for processing.
Now, these values will get mapped to ZZZ with the missing ParkName values. Then they will be turned into true nulls by the second NullAttributeMapper.
Challenge
You still need to filter out the null ParkNames and RefParkIDs and write them to a separate Feature Type (table) in the Geodatabase. Try this out; you'll need to do it to answer a quiz question below.
